Abstract
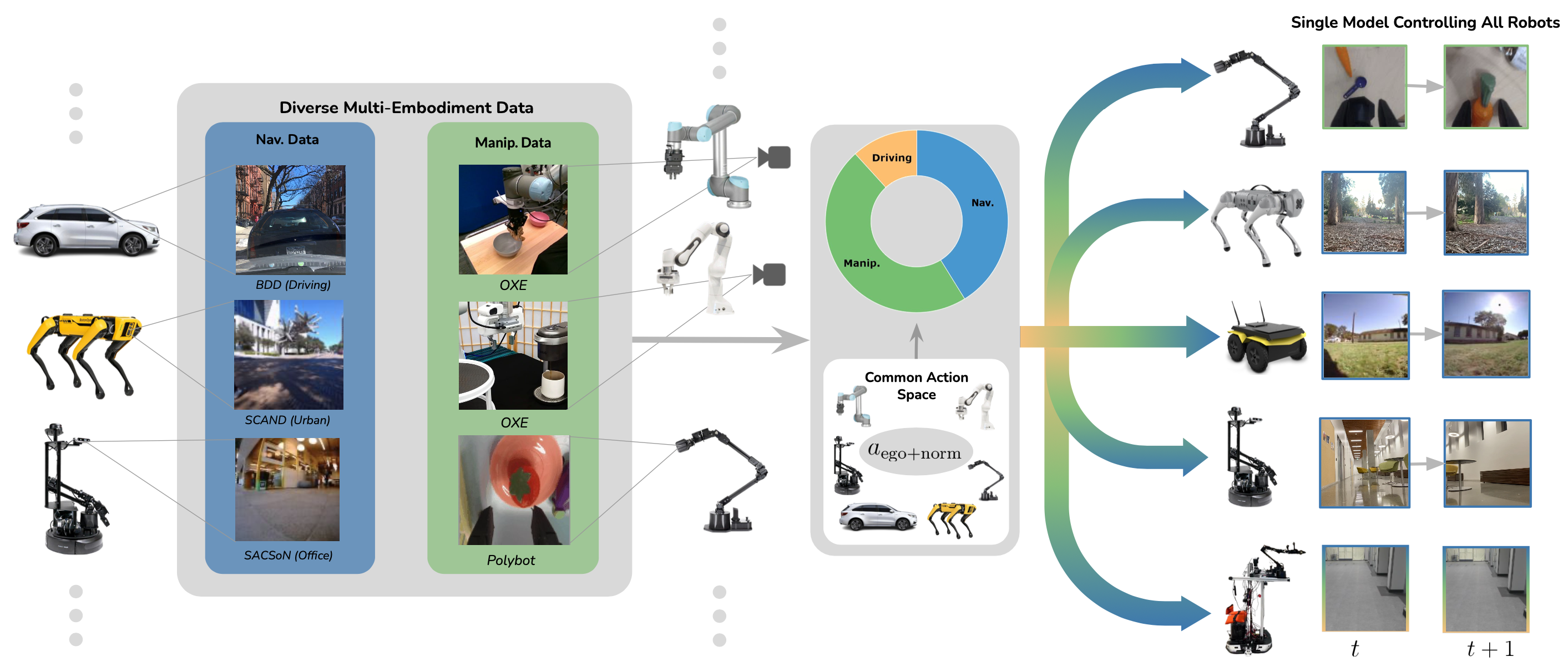
We train the first extreme cross embodiment policy capable of controlling a heterogenous set of embodiments, including robotic arms, drones, quadrupeds, mobile bases, and mobile manipulators.
We conduct over 1000 experiments to empirically characterize the effects of dataset size and variability, model size, and architecture choices. Our experiments reveal that policies co-trained with all manipulation and mobile data demonstrate an average of 20% improvement over 5 different manipulation tasks than training with manipulation data alone, and a 5-7% improvement over 4 different navigation platforms.
We then show that our policy can generalize to a mobile manipulator without any data specific to this embodiments.
Video
Manipulation and Navigation as Unified Goal-Reaching
While manipulation and navigation seemingly differ significantly in terms of hardware, observations, and action representations, they contain many similar sensorimotor principles. For example, both domains require the learned robot policy to have an understanding of collisions and geometry. Both domains also require the agent to perform some form of visual servoing. We leverage these insights to pose manipulation and navigation as a single goal-reaching task.
Generalization to Novel Manipulation Tasks
Co-training with navigation data allows for 20% improvement in a goal-conditioned grasping compared to a manipulation-only policy over 5 tasks. The policy is evaluated on 5 objects that were not seen in the training dataset, and is tasked with grasping the correct object given its goal image.